ENCODE Lab

About Us:
The ENCODE Lab is led by Dr. Huan Wang, a Tenure-Track Assistant Professor in the AI Department at Westlake University. Our lab is dedicated to advancing the field of Artificial Intelligence by focusing on creating efficient and effective AI solutions.
Research Focus:
Our research focuses on Efficient AI in vision and language modeling:
- high-level vision: image classification, detection, etc. [GReg, PaI-Survey, TPP];
- low-level vision: image restoration [ASSL/GASSL, SRP, ISS-P], stylization [Ultra-Resolution-NST], snapshot compressive imaging [QuantizedSCI, MobileSCI];
- 3D reconstruction and rendering, NeRF: [R2L, MobileR2L, LightAvatar];
- image generation with diffusion models or AR models: [SnapFusion, ARPG];
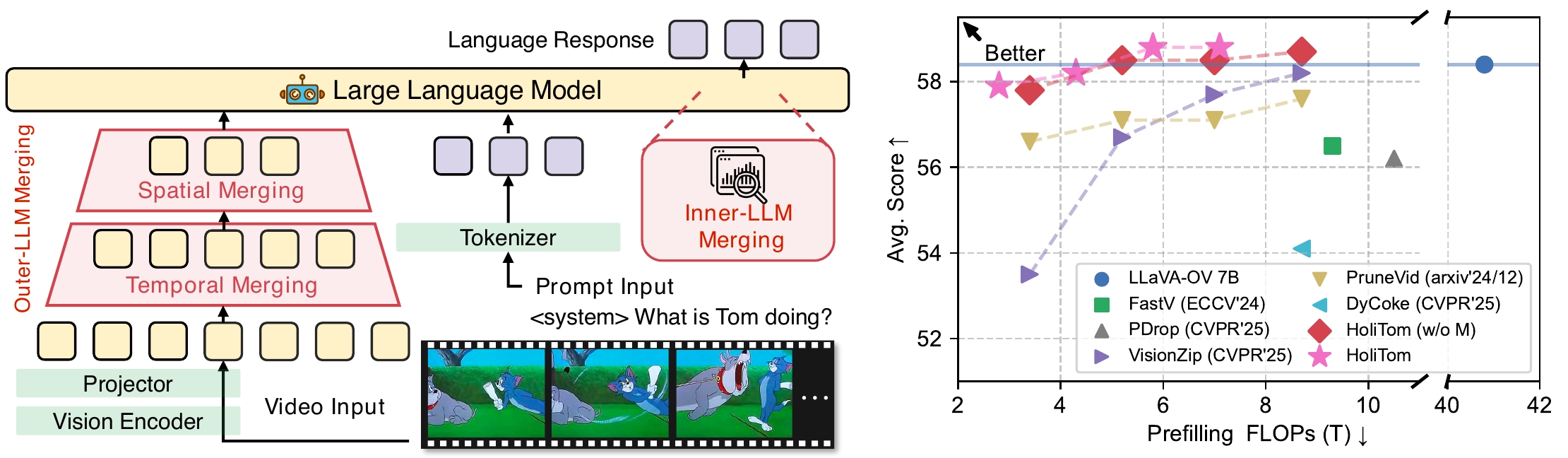
- LLMs / MLLMs: [DyCoke, HoliTom, Survey].
Our Mission:
Our mission is to advance AI by creating efficient, broadly applicable methods and models. We’re dedicated to driving both theoretical innovation and tangible solutions for diverse real-world problems.
News
| 2025/09 | [NeurIPS'25] 4 papers accepted by NeurIPS 2025 in the field of efficient and reliable AI. Congrats to my students and collaborators! 🎉 Two of them are public already:
|
|---|---|
| 2025/06 | [Award-to-Students] 🎉Congrats to my PhD student Keda Tao on receiving the “2025 Westlake University Xinrui Award (西湖大学博士研究生新锐奖)” (only 2 recipients in AI among all the 2025 Fall PhD students in School of Engineering). |
| 2025/02 | [CVPR'25] DyCoke is accepted by CVPR’25! Congrats to Keda!🎉 DyCoke is a training-free, plug-and-play token compression method for fast video LLMs: 1.5x wall-clock inference speedup and 1.4x memory reduction with no performance drop. [arxiv] [code] |
| 2025/02 | [Preprint] Can diffusion models blend visual concepts that are semantically very unsimilar (e.g., an orange and a teddy bear)? Yes, we introduce FreeBlend, a new method to blend arbitrary concepts. [arxiv] [code] [webpage] |
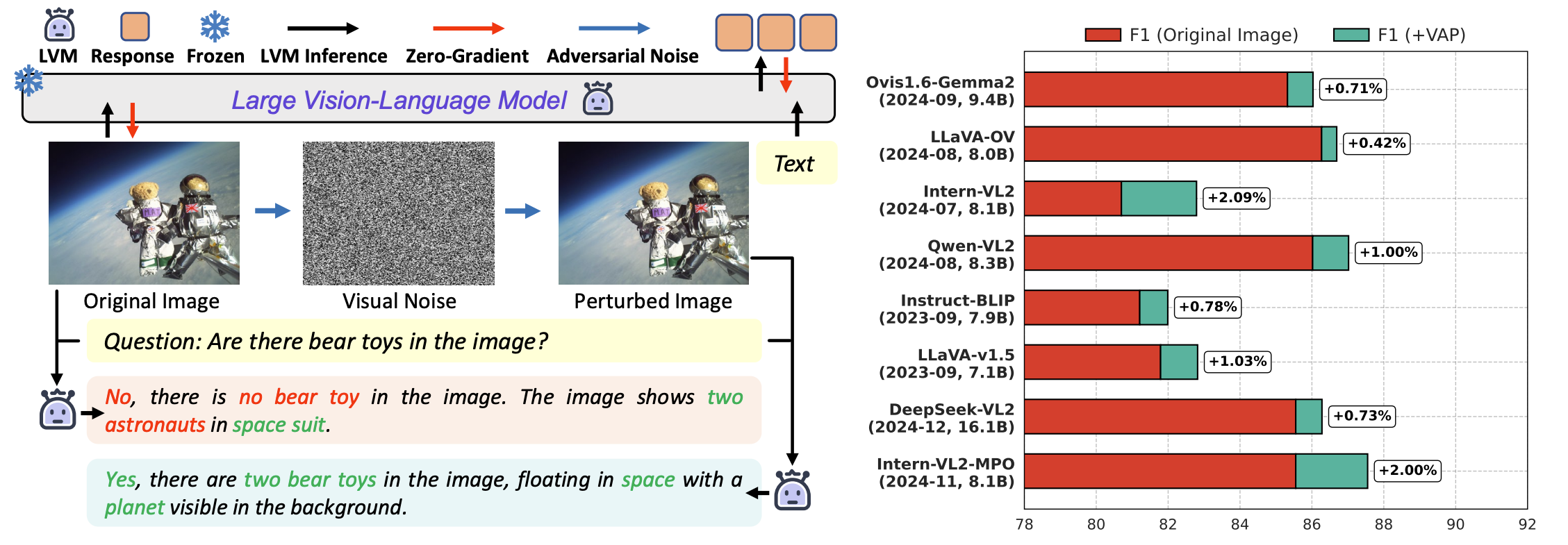
| 2025/01 | [Preprint] Adversarial visual noise is always malicious to our models like “poison”? No, we find it can also be a cure to mitigate the hallucination problem of VLMs. [arxiv] [code] [webpage] |
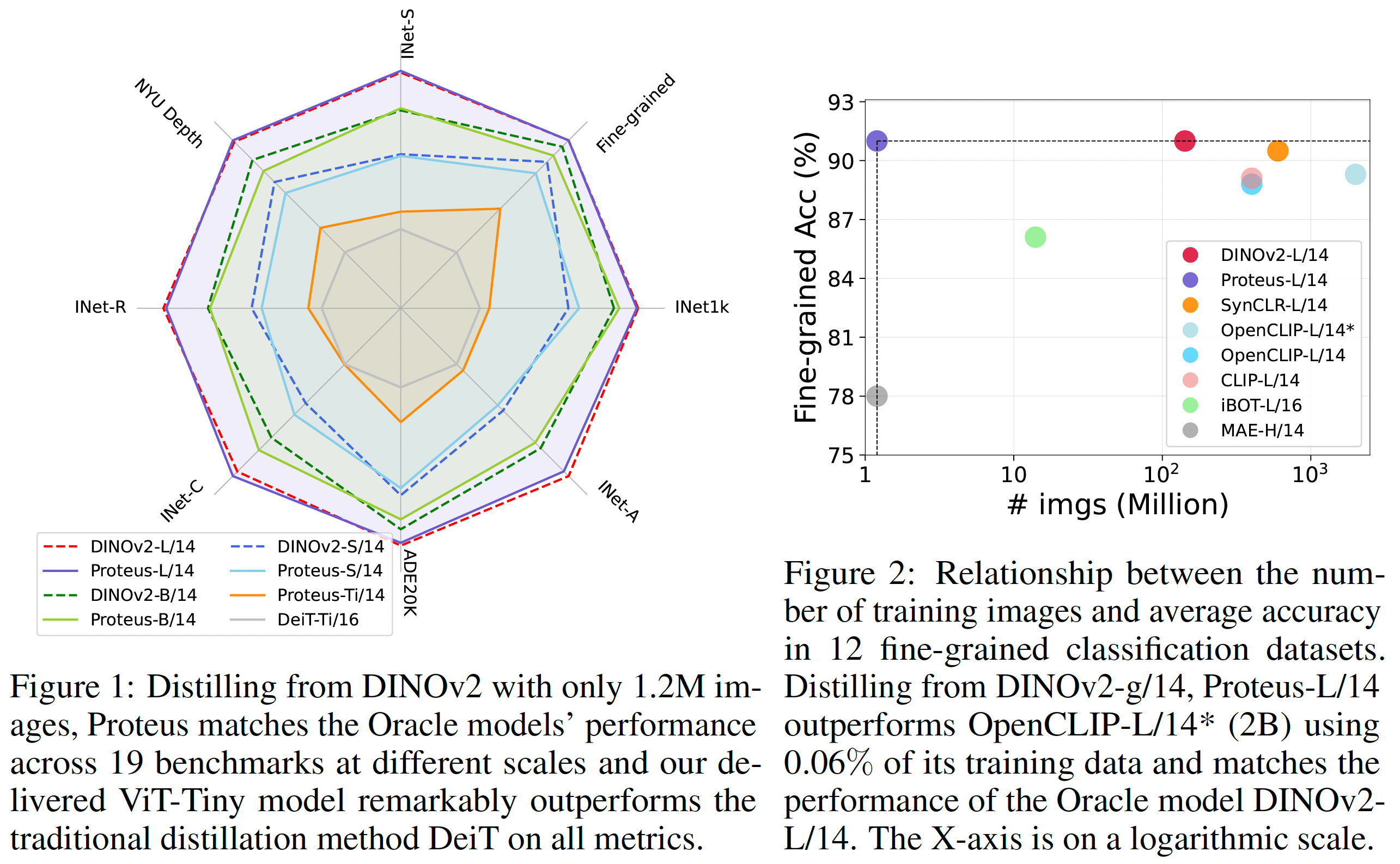
| 2025/01 | [ICLR'25] One paper about distilling large foundation models with low cost “Compressing Vision Foundation Models at ImageNet-level Costs” is accepted by ICLR’25. Thanks to the lead author Yitian! |
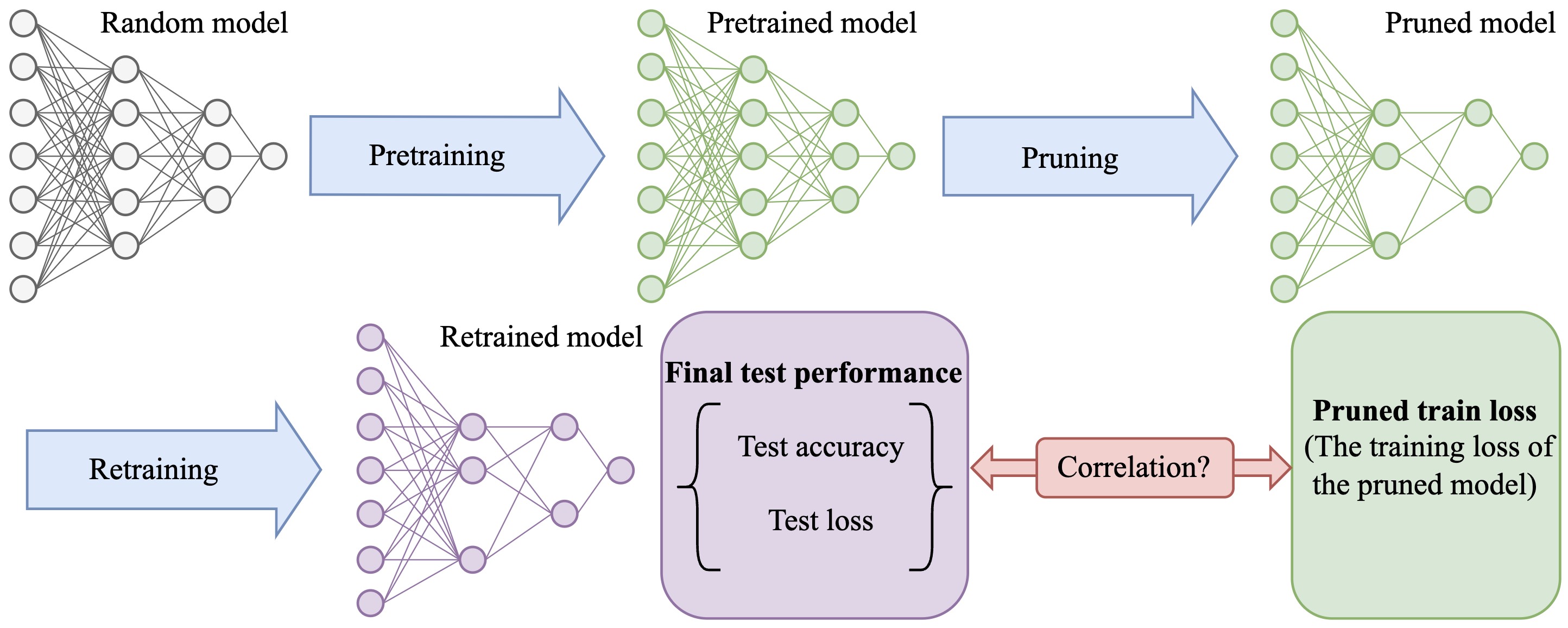
| 2024/12 | [Preprint] We present empirical evidence to show that oracle pruning, the “ground-truth” pruning paradigm that has been followed for around 35 years in the pruning community, does not hold in practice. [arxiv][webpage] |
| 2024/07 | [NeurIPS'24] We introduce a training framework Scala to learn slimmable ViTs. Using Scala, a ViT model is trained once but can inference at different widths, up to the need of devices with different resources. The project is led by Yitian. Congrats! |
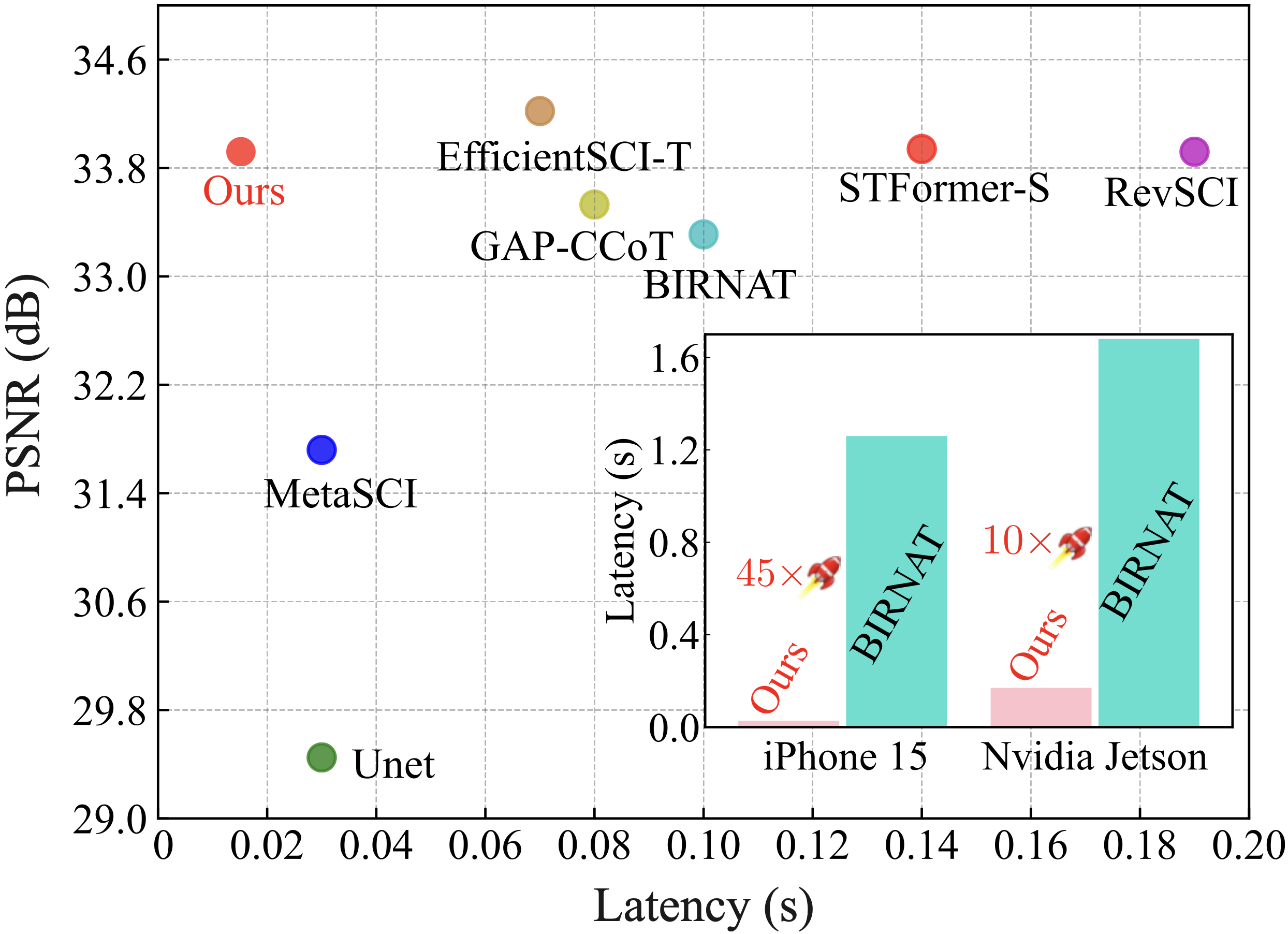
| 2024/07 | [MM'24] We present the first real-time on-device video SCI (Snapshot Compressive Imaging) framework via dedicated network design and a distillation-based training strategy. Congrats to Miao! |
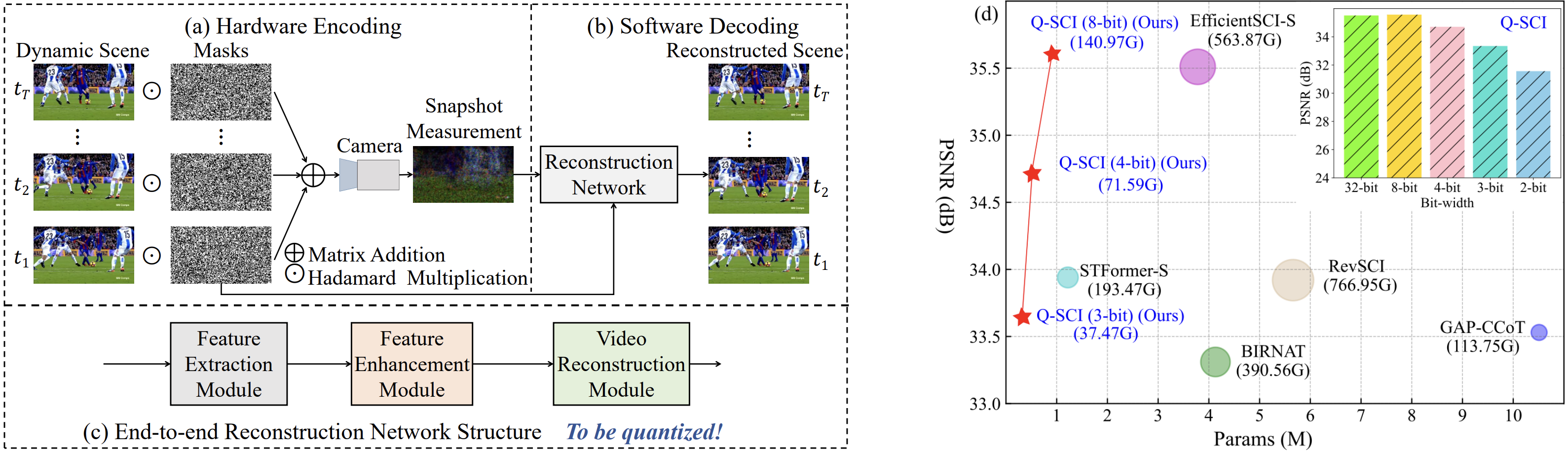
| 2024/07 | [ECCV'24] One paper about efficient video SCI (Snapshot Compressive Imaging) via network quantization is accepted by ECCV’24 as an oral. Congrats to Miao! [code] |
Latest Posts
Selected Publications
- arXiv’25/07
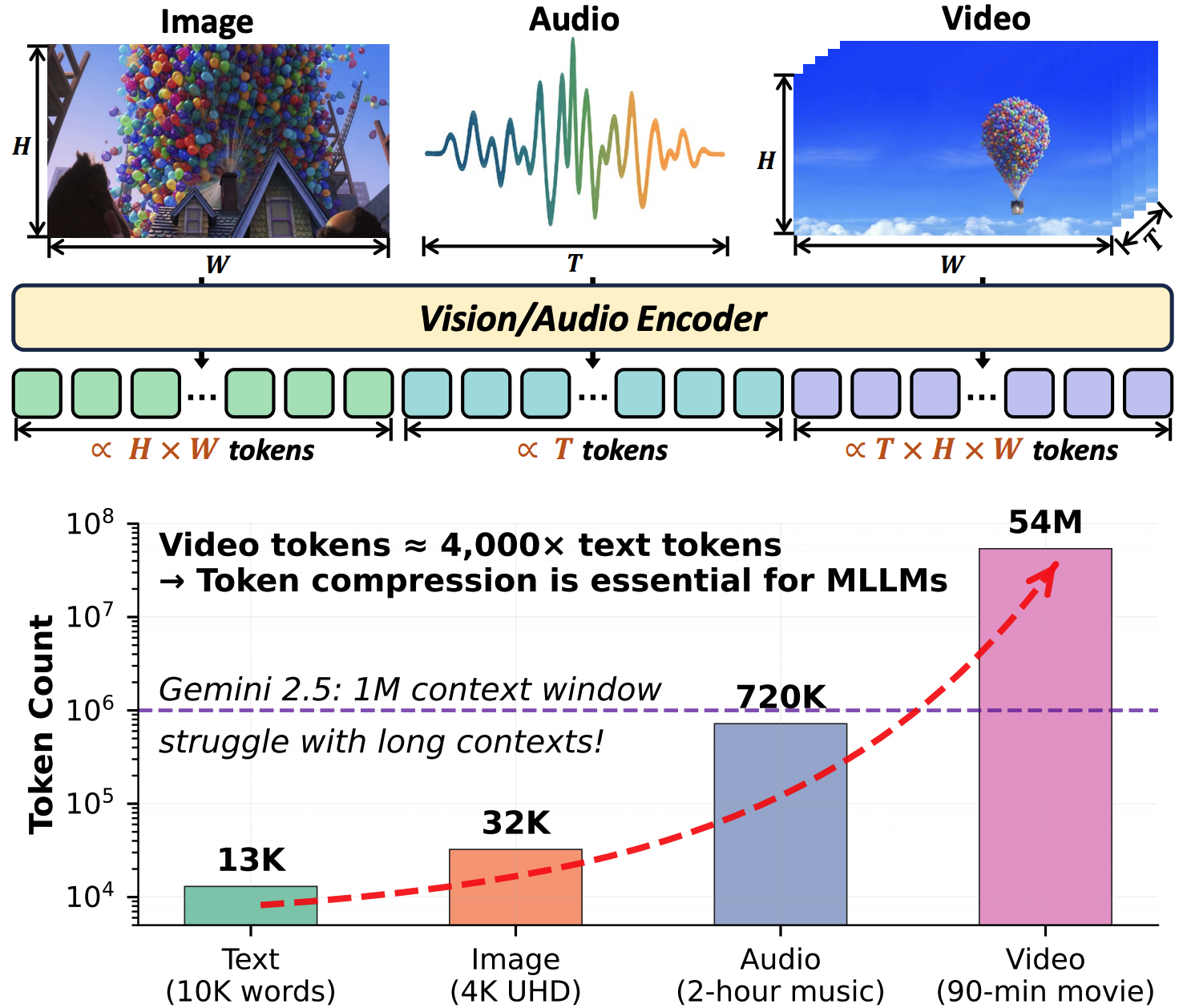 When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and AudiosarXiv preprint arXiv:2507.20198, 2025
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and AudiosarXiv preprint arXiv:2507.20198, 2025