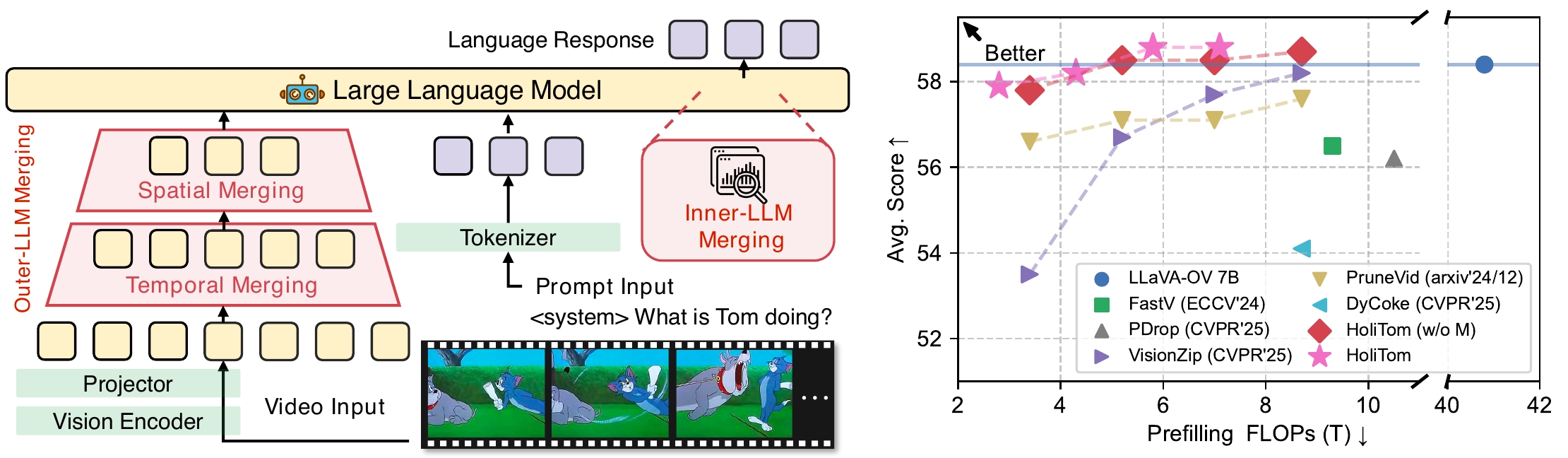
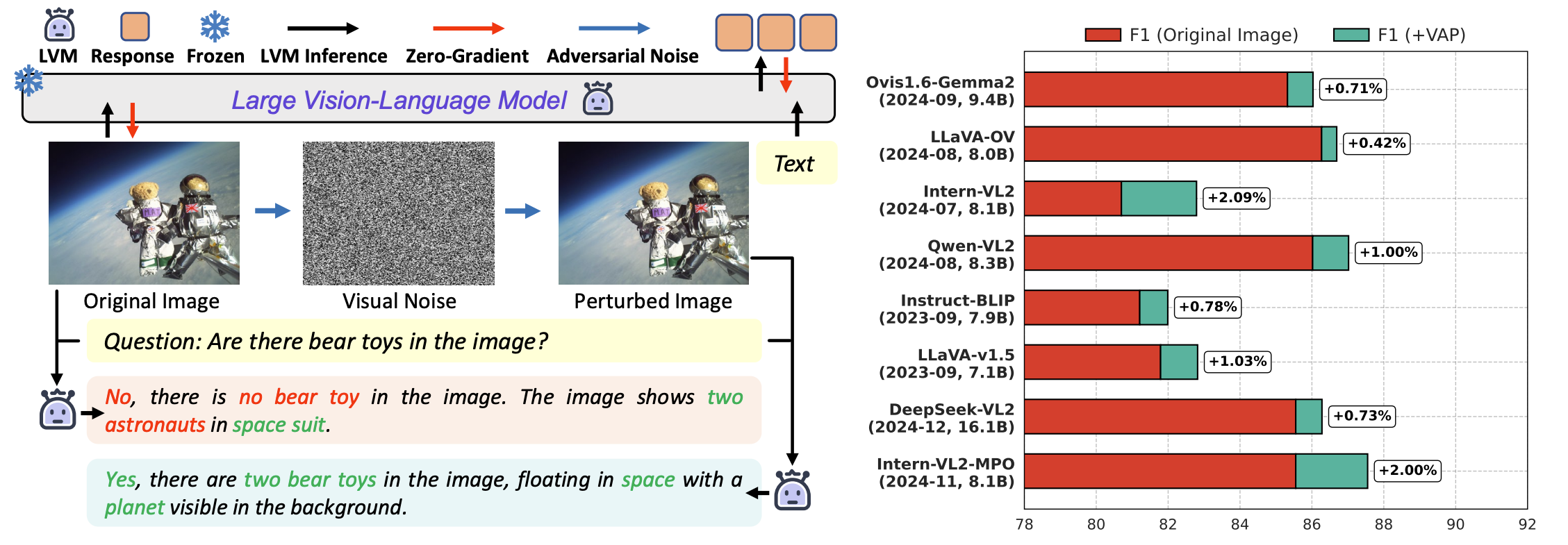
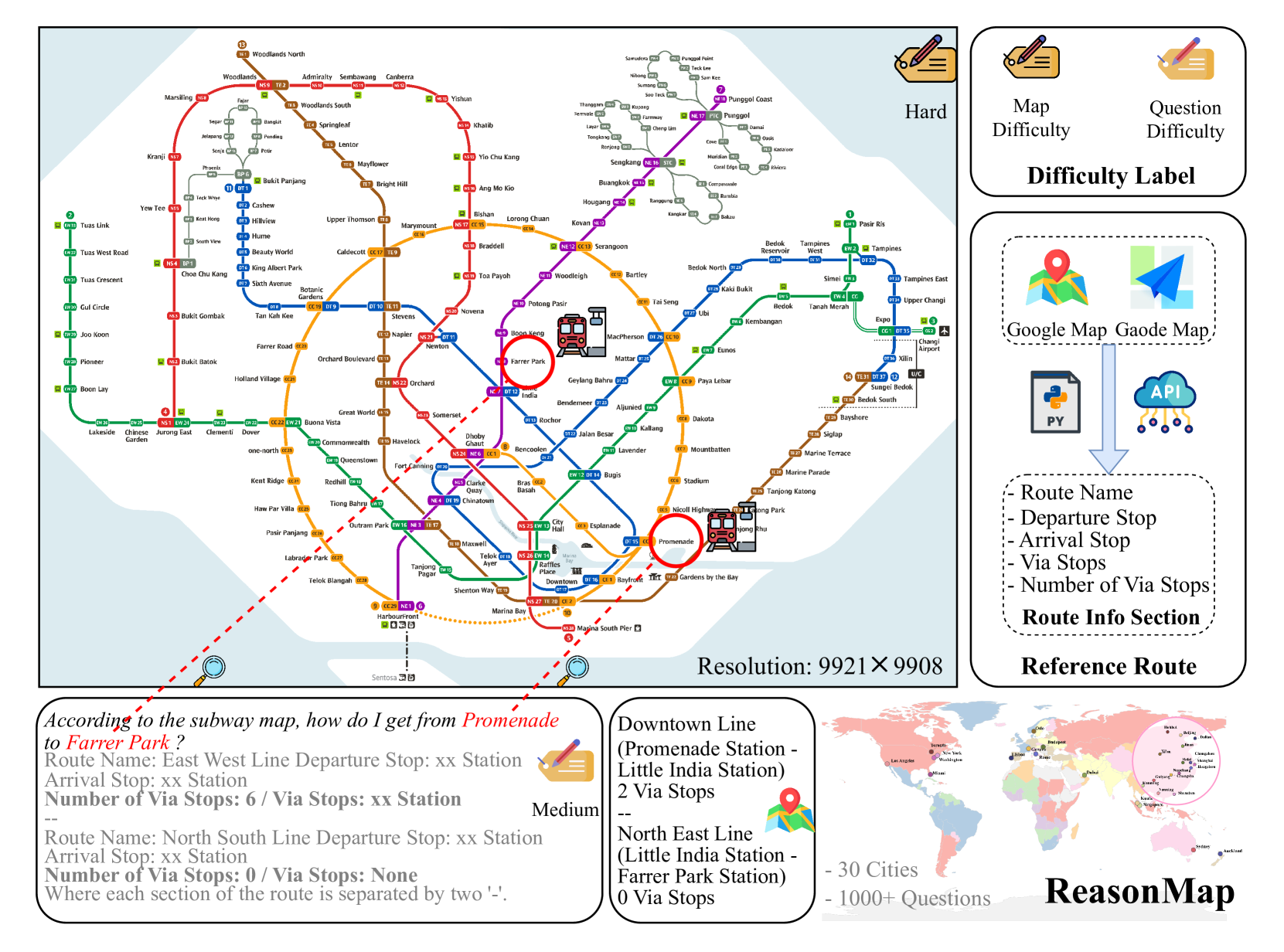
Publications
publications by categories in reversed chronological order.
2025
- arXiv’25/07
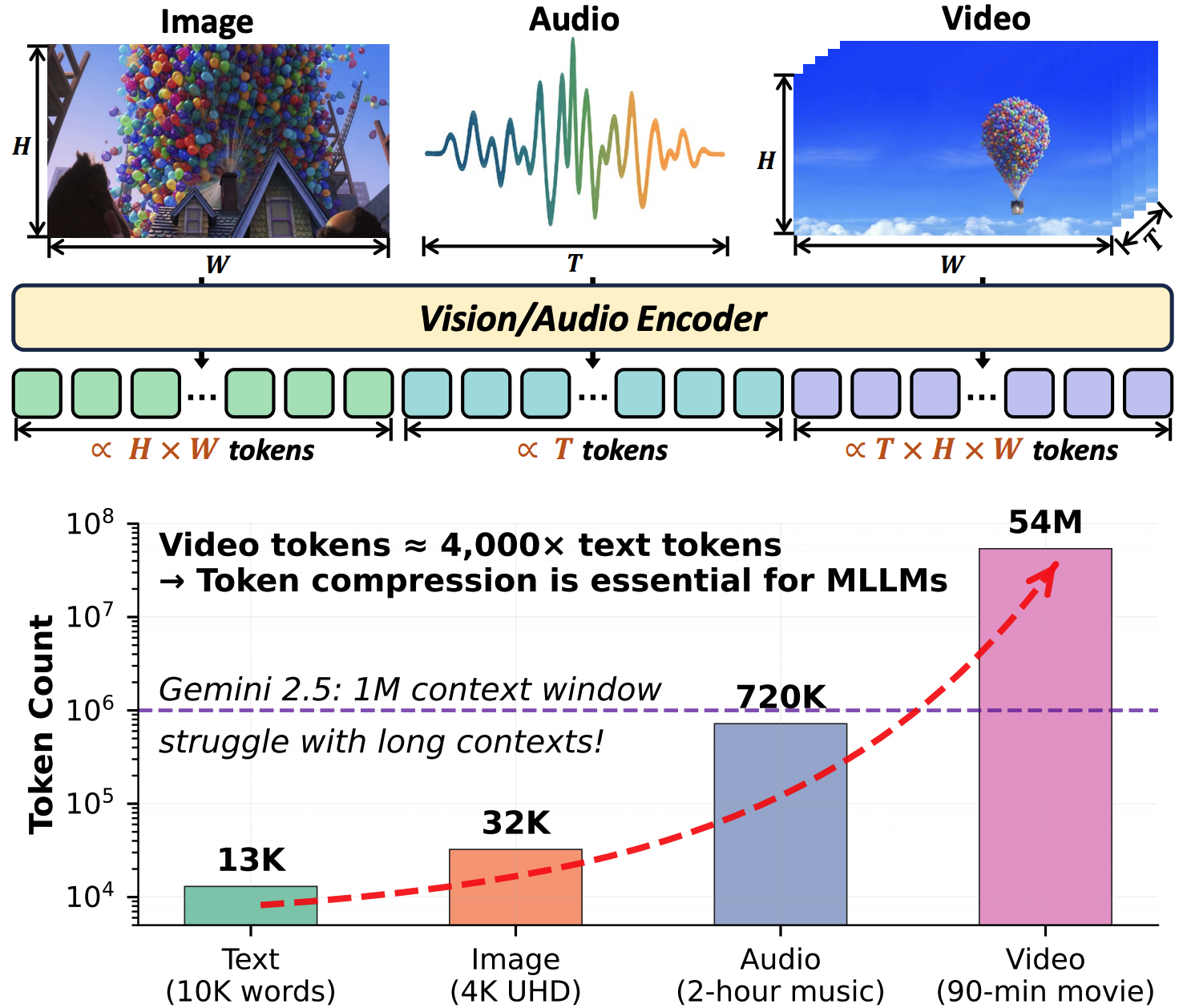 When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and AudiosarXiv preprint arXiv:2507.20198, 2025
When Tokens Talk Too Much: A Survey of Multimodal Long-Context Token Compression across Images, Videos, and AudiosarXiv preprint arXiv:2507.20198, 2025
publications by categories in reversed chronological order.